Large Language Models (LLMs) have achieved impressive results on everything from writing fiction to explaining complex code. However, the performance of LLM agents drops precipitously once the task requires long range planning or up-to-date knowledge of the world.
Code generation is one such task, involving diverse specifications, constraints, and tests. These requirements, even if simple, can make autonomous code generation difficult. It gets harder when the specifications conflict or are ambiguous. Even if the requirements are rigorously sound, the probabilistic nature of language models can lead to buggy code, thereby warranting careful human supervision. The code has to both compile1 and correctly solve the problem. Generating correct code is hard and even powerful systems like GPT-4 will frequently fail at this task.
Objective-driven AI is a paradigm that promises to address the planning and reasoning shortcomings of LLMs2. In this post, we explain how tree-based reasoning and reflection methods can improve the quality of generated code over non-objective-driven methods. To see objective-driven reasoning in action, take a look at this demo, where we visualize how tree-based reasoning helps a model explain and correct erroneous code, while solving the HumanEval3 benchmark.
Finally, we open source Branches – a library to visualize planning and reasoning with LLMs, which we used to build the demo. As both a prototyping tool and a webapp, Branches is intended to be compatible with general graph-based reasoning algorithms. We hope it will be a useful tool for the community as we work together to explore and develop objective-driven agentic systems.
The dangers of thinking fast
Before we focus on trees, let’s discuss the more common method of simply asking a chatbot like gpt-3.5-turbo or gpt-4 to produce code. These models do a good job at getting the answer right, but only sometimes. Other times they make logical or algorithmic errors. This is not desirable when you are dealing with mission-critical problems.
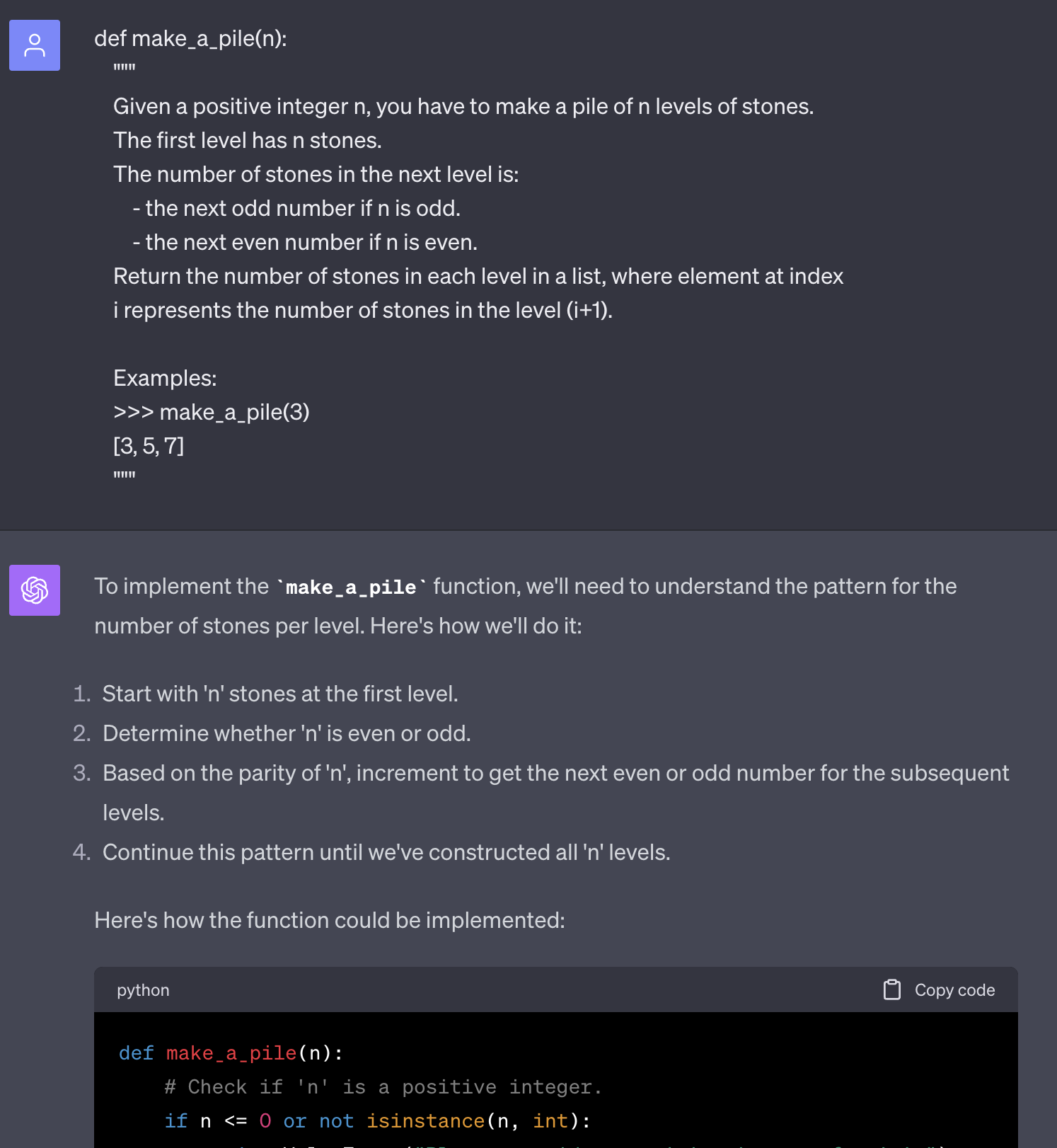
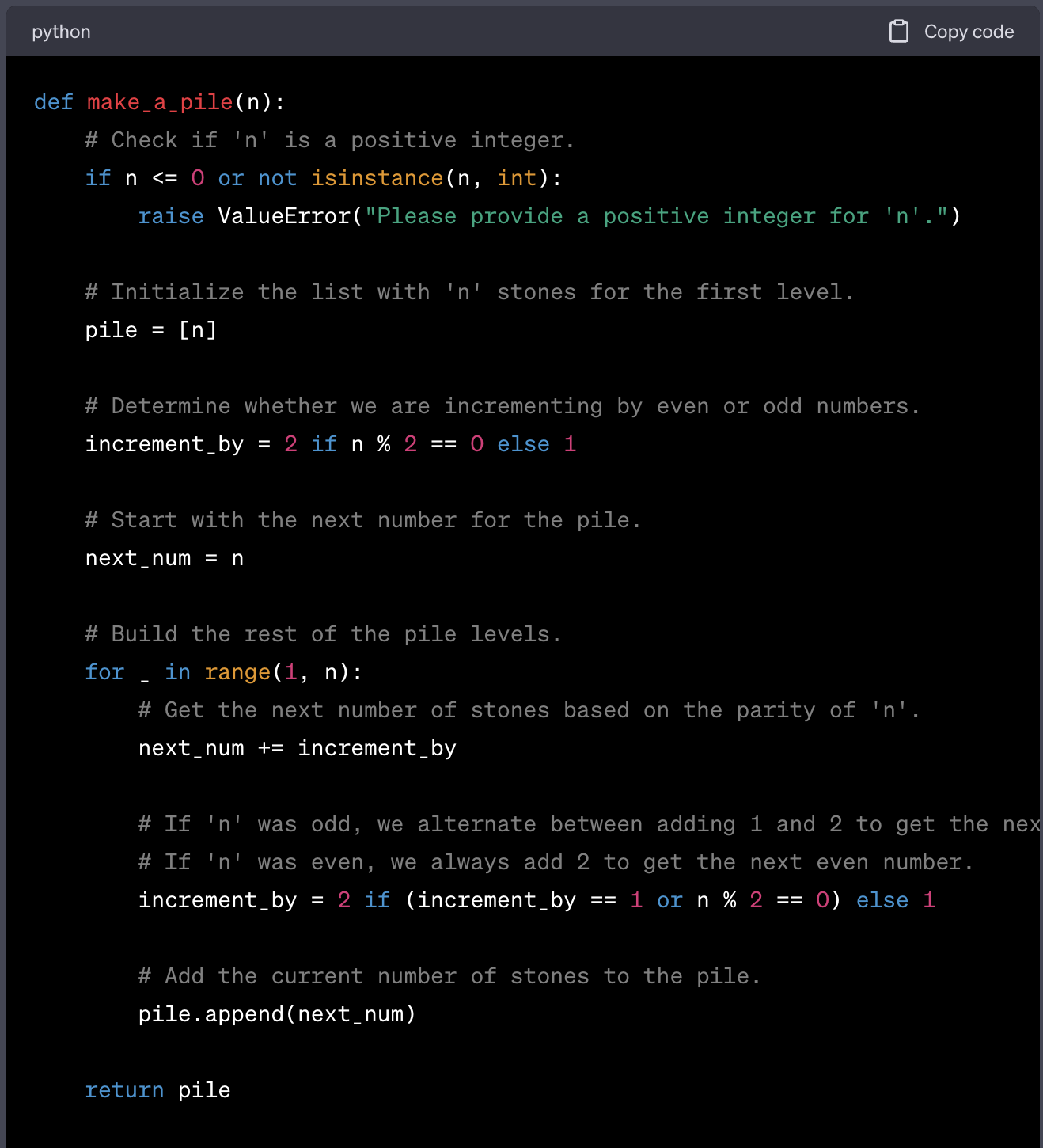
make_a_pile(3) == [3, 5, 7] even though it is explicitly mentioned in the docstring, it erroneosly returns [3, 5, 6].
This is similar to humans, who don’t always get a program right in the first try. The problem is partially that large language models (LLMs) generate code line by line and when one of the lines is wrong, there’s a greater chance that the rest of the generation is also tainted. This errorenous token or sequence starts the hallucination train. We need a way to catch the LLM as soon as it starts making a mistake, stopping the hallucination train before it can leave the station.
Improving code generation using trees and reflection
A simple way to reduce failures in LLMs is to think step by step. In this framework, the task is simplified into small steps and processed sequentially. This is a very rough approximation to how a person breaks down a problem in order to solve it. Prompting an LLM to think step by step is one example in a wider realm of methods for structuring an LLM’s responses into a series of intermediate steps.
However, standard few-shot and chain-of-thought prompting don’t go far enough. They still suffer from error propagation, and to improve their success rates, one often has to re-sample the answer multiple times. It would be faster to resume from the point of an error, rather than re-sampling the entire sequence.
Being able to restart from the point of error is one motivation for tree-based methods. Branching out to explore solutions from the point of failure, and exploring multiple paths to the solution, are core ideas behind Tree of Thoughts (ToT)4. The concept of breaking a task down into multiple reasoning steps and potentially including verification steps is also explored in Language Model Cascades. These methods work by exposing intermediate steps to outside evaluation, thus empowering objectives to guide the overall reasoning process.
In this post, we focus on a particular example of objective-driven AI which uses tree-based methods augmented with feedback from Python interpreters. Through self-evaluation and self-reflection, these methods unlock autonomous code agents which can detect hallucinations and fix them5.

Branches: prototyping graph-based objective-driven AI
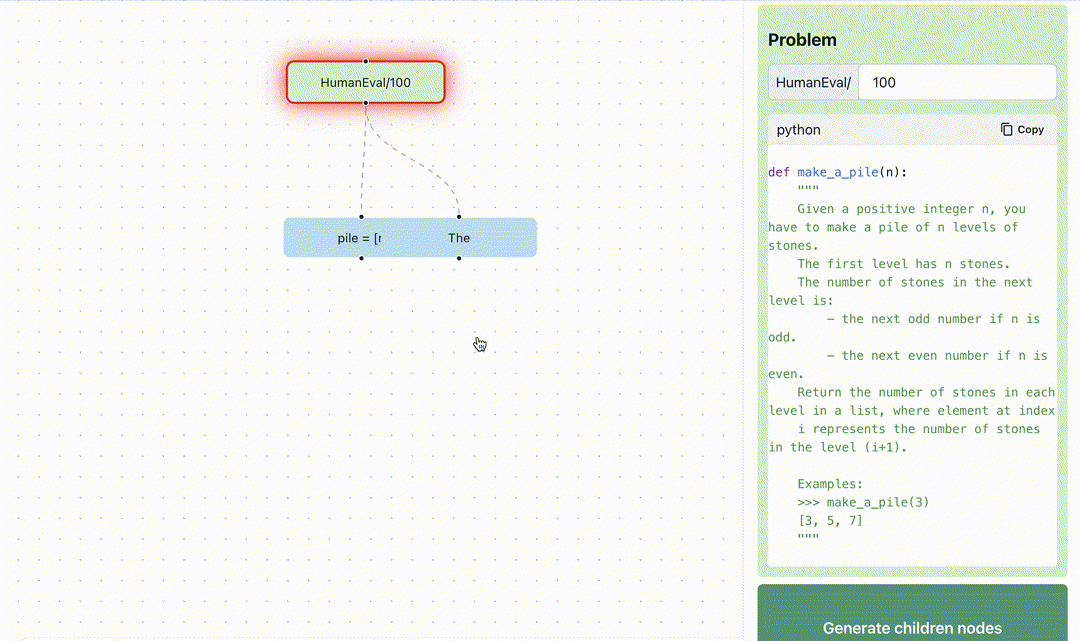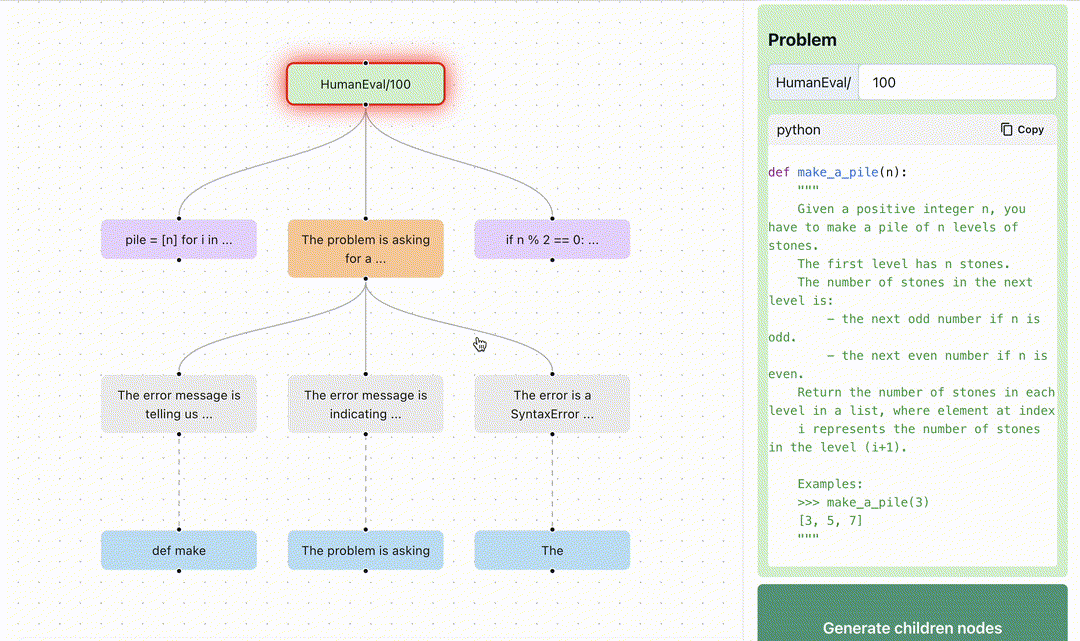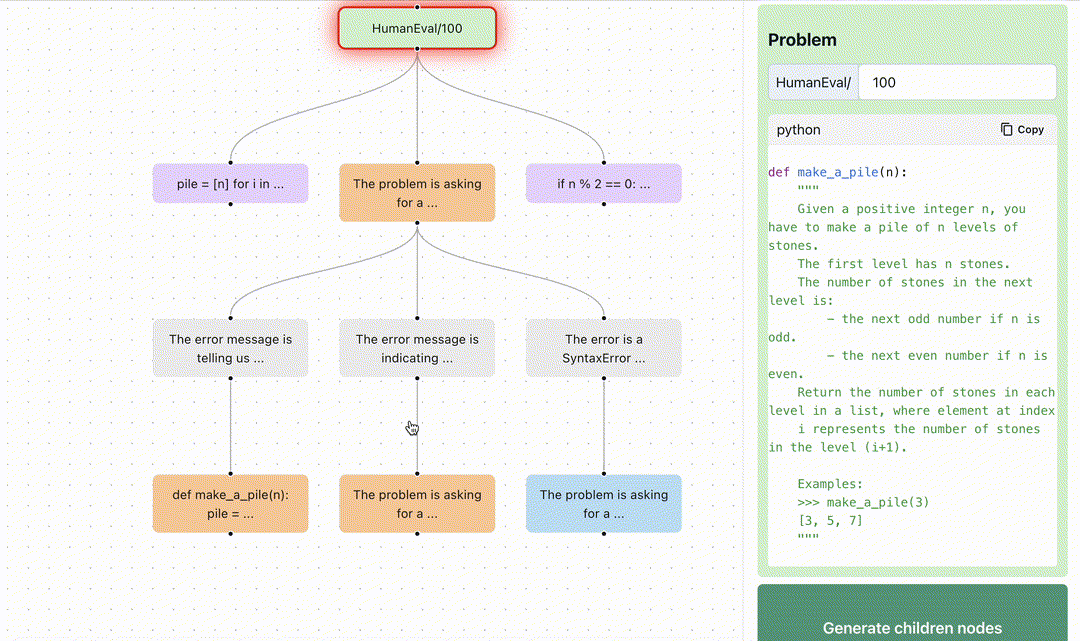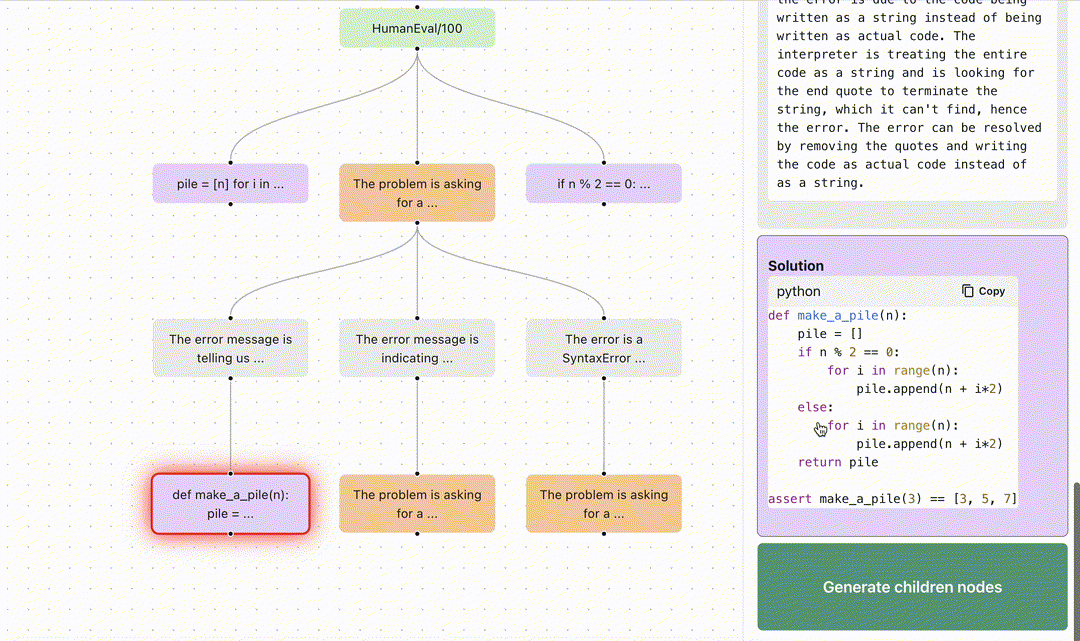
At Normal Computing, we believe keeping humans in the loop is essential for the long term success and utility of AI. Key to maintaining this feedback loop is providing developers with better tools and interfaces for building and interacting with AI systems. In this spirit, we are excited to open source Branches. In this project, we provide tools to visualize graph-based reasoning algorithms relative to different feedback-driven benchmarks. Today, we have provided two demos which visualize the application of tree-based reasoning to HumanEval and Game of 24. The AI model scores the intermediate steps, explains the errors at each step, and uses the results to decide how to prune the frontier.
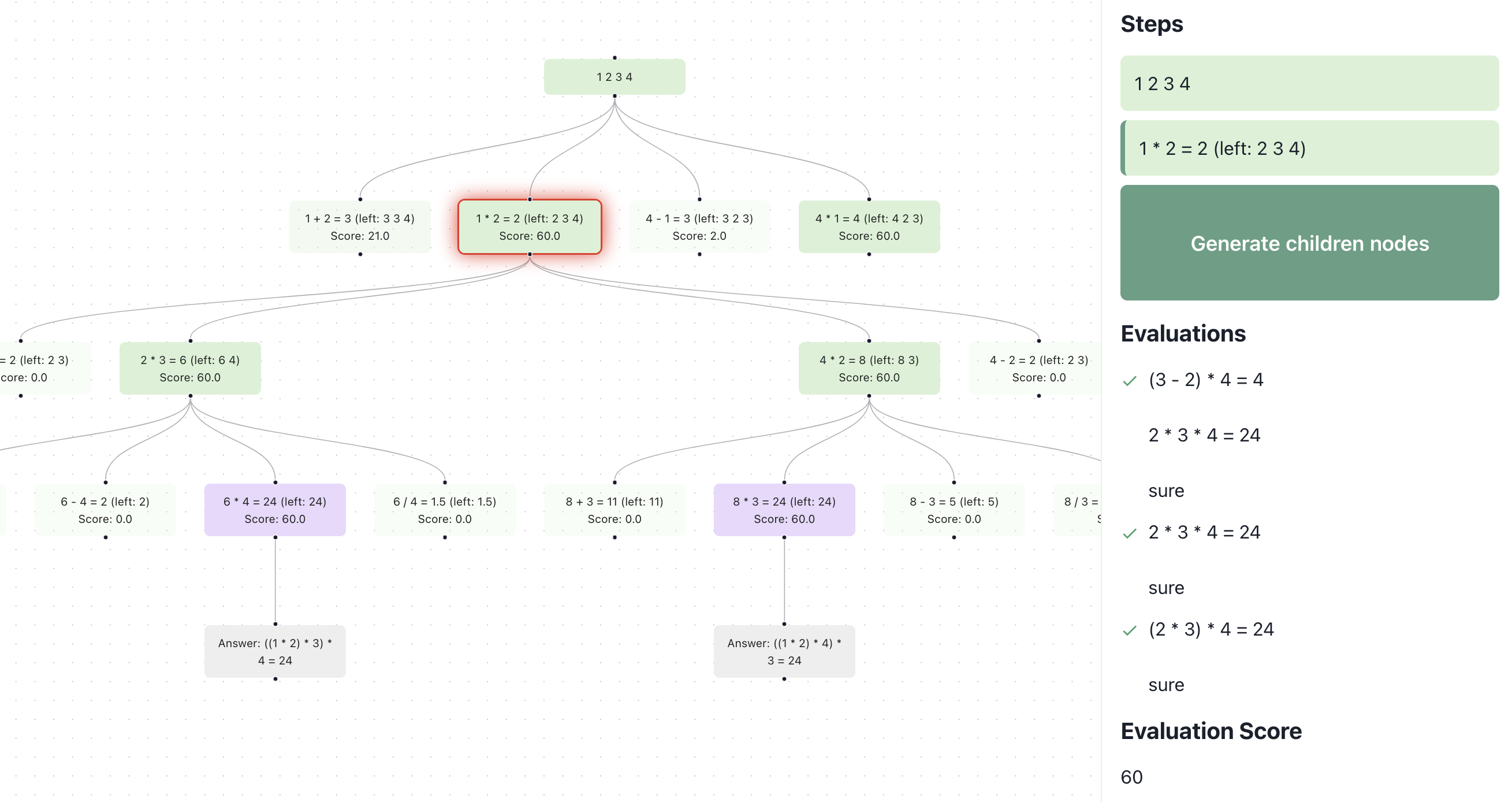
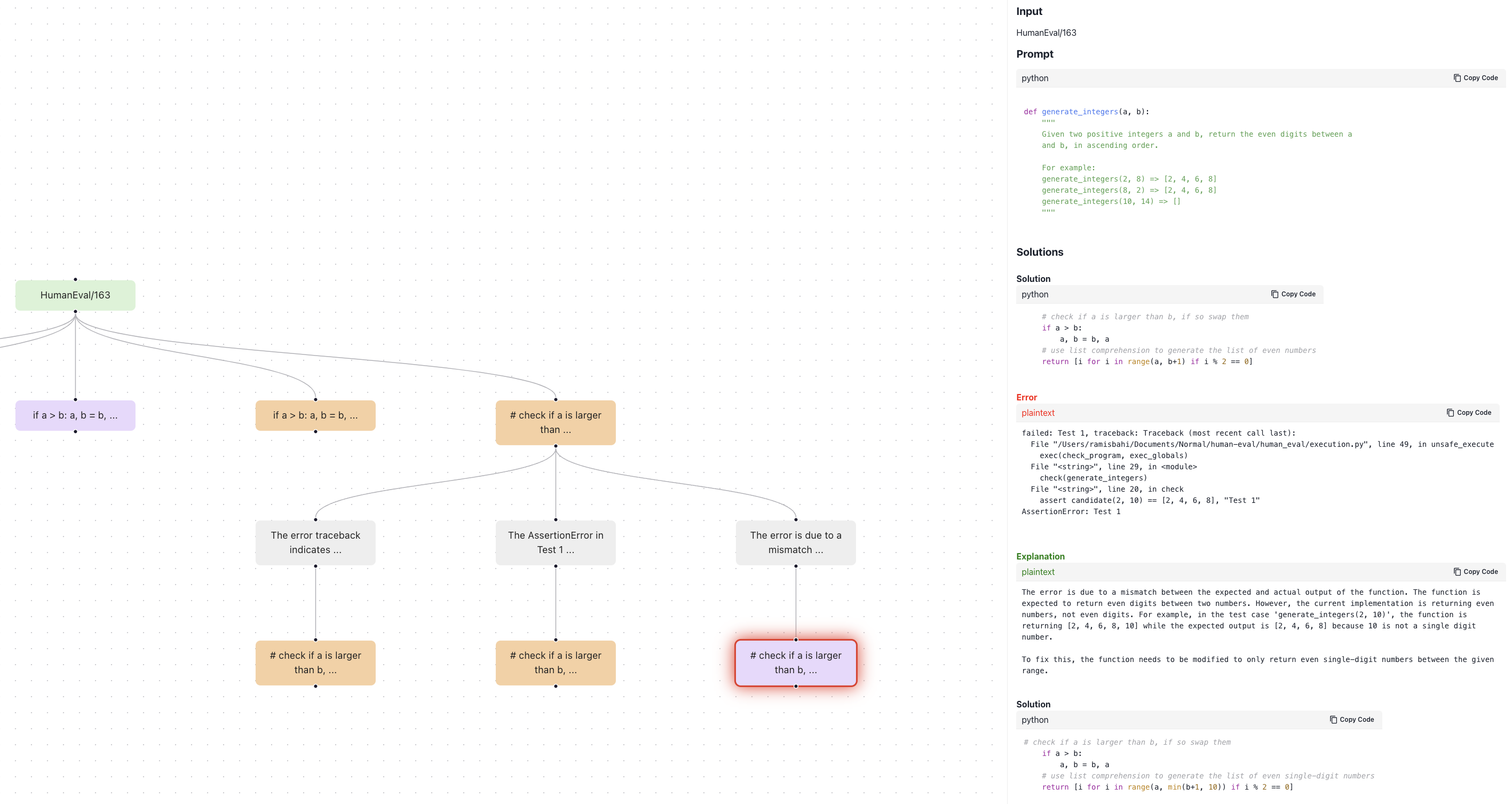
branches. Here, we see the search is broken into steps where each step is self-scored by the LLM.We use the ToT paradigm to solve coding problems on the HumanEval dataset6 for Python code generation. As seen in the below image, the model samples multiple answers and runs test cases against them. If it fails any of the test cases or generates invalid code, an external Python code-interpreter provides rich feedback including the entire traceback7. This error traceback is reflected upon to summarize the mistakes and provides directions to correct its code. This significantly improves success rates, simply by incorporating real world feedback.
You can explore the Tree of Thoughts reasoning process applied to HumanEval in our interactive demo. This strategy differs from OpenAI’s Code Interpreter, which currently doesn’t take back rich feedback, and therefore only knows that the code has failed.
What does the future hold?
This demonstration is a relatively small step amongst our broader push of the frontiers of objective-driven AI. Here, we’ve made accessible new ways to develop and evaluate LLM planning and reasoning algorithms. In particular, we focused on tree methods in the context of code generation tasks with feedback. Below are some of the ways that we envision making such tree methods faster, more accurate, and more collaborative:
- Fast Inference: Since prompt headers remain constant across nodes, we hypothesize that inference can be sped up by using key-value (KV) caching8 across prompt completions. Support for KV-caching across prompts is not ubiquitous from major LLM providers, but can be addressed with careful engineering.
Extended Memory: As tasks become longer and more complex, the requirements for the amount of feedback quickly outgrow the context length of many models. Memorizing transformers are one way of breaking free of the standard context window constraints (which we recently generalized with Extended Mind Transformers). Potentially, the extended memories can be leveraged to enhance the search process.
Human Feedback: Incorporating human feedback would enable bespoke qualitative objectives to drive the exploration process. Future work can account for this feedback both in terms of the graph-based search algorithms and in the demo visualizations.
Acknowledgments
We would like to give a huge shout-out to Paradigm’s Flux, which formed the basis of our visualization demo.
Footnotes
With the
outlinespackage we can guarantee that generated code will compile. But this does not, in and of itself, guarantee that it is correct↩︎ToT generalizes methods like chains of thoughts, verification, density as well as other methods.↩︎
For more background on explainability in AI and hallucination detection, please see our recent blog post↩︎
This is a test set of 164 Python problems.↩︎
Summarized neatly here: https://realpython.com/python-traceback/↩︎