Eliminating hallucinations (fast!) in Large Language Models with Finite State Machines
In this blog, we introduce our method for regex-guided generation implemented in Outlines
engineering
Author
Rémi Louf, Phoebe Klett, and Dan Simpson
Published
August 4, 2023
A quick word from 2024
Since this post was first published last year, there has been a lot of exciting activity in the constrained generation space.
Our good friends at .txt have continued the outlines mission and have made a number of really exciting extensions
The folk at Predibase have showed that outlines combined with LoRA fine-tuning makes a marked improvement in performance for JSON generation!
We have continued our mission to build structures on top of open-source large language models that allow for reliable generation!
Welcome to the (Finite-State) Machine
Anyone who has used AI assistants like ChatGPT for generating code will have noticed that while it often does an excellent job, it will occasionally throw out something that is not syntactically correct, or even reasonable.
In general, despite reliability issues like unpredictable factual errors or “hallucinations”, large generalist models like ChatGPT continue to awe, reaching into early applications and use-cases. However, hallucinations which cause these large models to divert from critical requirements like reporting or audit log formats, valid programming language syntax, or even chemical equation syntax can be barriers to adoption for complex domains1.
Overcoming these limitations for some of the most valuable problems will require techniques for efficiently and transparently controlling these models, while surfacing explainability and risk-conscious reasoning.
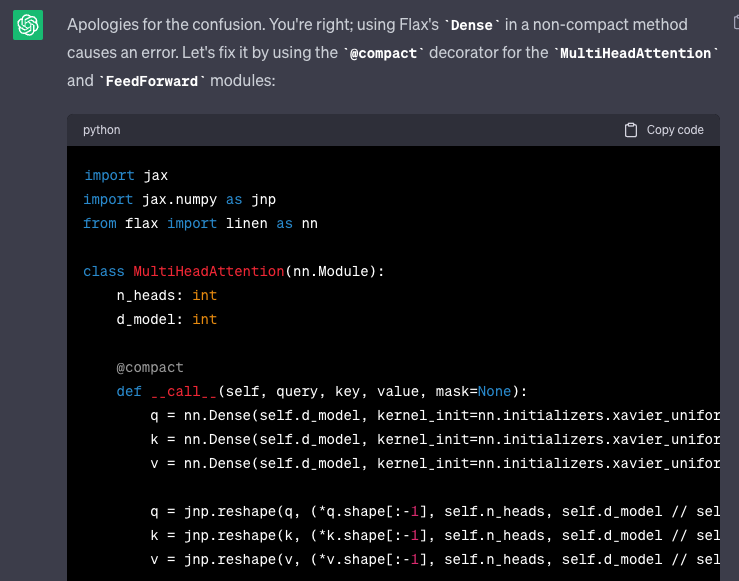
With that, now to a simple example where ChatGPT3.5 forgets to import a function from a module when defining a transformer in flax. We will see how the nexus of algorithms and infrastructure can actually deal with these issues. To get to this point, I had actually prompted it several times to fix more obvious errors2.
Part of a ChatGPT3.5 generation that doesn’t define the function compact when defining a transformer using the flax library.
This means that although the code generations are often excellent, they cannot be trusted without careful human modeling. There are innumerable examples across the field. The Manhattan project of our time, AutoGPT, has an issue label dedicated to incorrect JSON outputs.
If that wasn’t enough, the models (especially those fine-tuned with RHLF) tend to be very chatty, which can make answer extraction tricky even on simple numeric tasks. Prompt artists have been working on ways to instruct models to make their outputs follow a given format but, as the AutoGPT example shows, the statistical nature of the generation process means these methods are also prone to failure. This makes these unbridled beasts hard to use in practical contexts. So people came up with ways to “guard” humanity against their creation’s failures, for instance by asking it to try again in cases when it gets it wrong. That’s the guardrails approach.
But that’s all very inefficient and time consuming.
Making guided generation possible
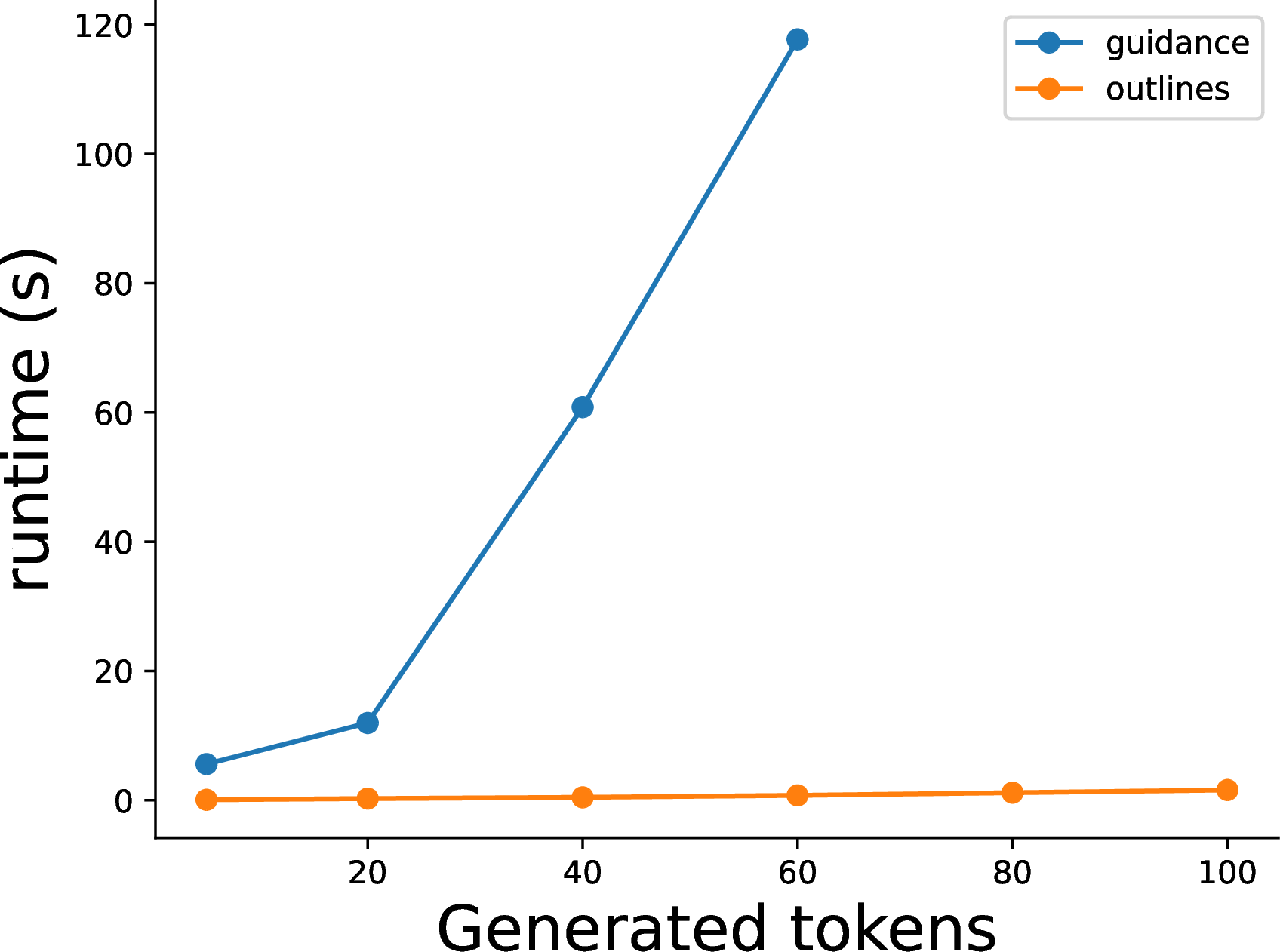
In this post, we will demonstrate a method that can constrain LLMs to generate only valid output! This can be done efficiently, effectively, and quite generally. In order to avoid too much complexity, we are going to focus on generating text that matches a regular expression (regex) query. We have implemented efficient generation in our outlines library, and it is quite a lot faster on this topic than other libraries like guidance.
Comparison between regex-guided generation in outlines and guidance
All in all, outlines provides a powerful, flexible, and extensible tool for constrained language generation. It is also extremely fast: there is almost no overhead beyond the ordinary generation of text. Although we are focussing exclusively on regex-constrained generation in this post,it is definitely not the limit of this technique. In future posts (and future updates to outlines) we will show how similar ideas can be used to
generate text that conforms to a given pydantic or json schema; and
generate valid python, C++, SQL, verilog, pascal, rust, or really any computer language that has a context-free3 grammar (CFG). The CFG-guided generation method is outlined in this paper by Remi and Brandon.
Regex-guided generation in outlines
Just to show off the true power of constrained generation, let’s start with a weaker4 language model. As Jiang, et al. show in their recent work, compression algorithms can reasonably be used to cluster text. Richard Futrell pivoted off this observation to offer a “useless but mildly interesting” generative language model by noting that you could define unnormalized logits based on the length of a gzip compression. So let’s use this very very bad5 language model to generate constrained text. In particular, we will ask it questions about Moby Dick.
outlines is designed to work with any tokenizer/logit generator pair, so it is possible to use its powerful guided generation capability even for this strange model. All we have to do is register it. For OpenAI models or models from transformers, this is included out-of-the-box (using the outlines.models.text_completion.openai and outlines.models.transformers functions, respectively), but for a peek at the extensibility of outlines, we are going to show the code to incorporate a brand new (bad) LLM. All you need is a tokenizer and a machine for producing logits. From a practical point of view, this requires you to specialize a couple of default classes. We’ve folded the code because it’s a bunch of boiler-plate, but please click it open if you’re interested.
Code for registering a new LLM in outlines.
from typing import TYPE_CHECKING, List, Optional, Tuple, Unionimport torchimport gzipimport numpy as npimport scipyfrom outlines.models.tokenizer import Tokenizerclass ZipModel:"""Represents a zip language model."""def__init__(self, tokenizer, compressor, training: str, conversion: float, device: Optional[str] =None, ):self.training = trainingself.tokenizer = tokenizerself.compressor = compressorself.conversion = conversionself.device = device if device isnotNoneelse"cpu"def__call__(self, input_ids: torch.LongTensor, attention_mask: torch.LongTensor =None, temperature=1, ) -> torch.FloatTensor: batch_shape = input_ids.shape[:-1] input_ids =self.tokenizer.decode(input_ids) code_lengths_batched = torch.tensor( [ [len(self.compressor.compress(" ".join([self.training, inputs, v]).encode() ) )for v inself.tokenizer.vocabulary.keys() ]for inputs in input_ids ], dtype=torch.float32, device=self.device, ) code_lengths_batched = (-code_lengths_batched *self.conversion * (1/ temperature) ) code_lengths_batched = code_lengths_batched.reshape(batch_shape + (-1,))return code_lengths_batchedclass ZipTokenizer(Tokenizer):"""Represents a tokenizer for zip models."""def__init__(self, vocabulary: str, device: Optional[str] =None, ):self.device = device if device isnotNoneelse"cpu"self.pad_token_id =45self.eos_token_id =45self.eos_token ="<|endoftext|>"self.vocabulary = {v: i for i, v inenumerate(vocabulary)}self.vocabulary[self.eos_token] =self.eos_token_iddef encode(self, prompt: Union[str, List[str]] ) -> Tuple[torch.LongTensor, torch.LongTensor]:ifisinstance(prompt, str): prompt = [prompt] inputs = torch.tensor( [[self.vocabulary[i] for i inlist(prompt.lower())] for prompt in prompt], dtype=torch.int64, device=self.device, )return inputs, torch.ones(inputs.shape, dtype=torch.int64, device=self.device)def decode(self, token_ids: torch.LongTensor) -> List[str]:def find_key_by_value(dictionary, value):returnnext((key for key, val in dictionary.items() if val == value), None)return ["".join([find_key_by_value(self.vocabulary, tok) for tok in input_ids])for input_ids in token_ids ]def convert_token_to_string(self, token: str) ->str:return tokendef ziplm( compressor=gzip, vocabulary="qwertyuiopasdfghjklzxcvbnm,.;:1234567890@_\/ ", training="", conversion=np.log(256), device: Optional[str] =None,): tokenizer = ZipTokenizer(vocabulary=vocabulary, device=device)return ZipModel( tokenizer=tokenizer, compressor=compressor, training=training, conversion=conversion, device=device, )
We can now ask this model a question about Moby Dick. (That the model answers this question correctly should not be taken as evidence of either intelligence or knowledge of Moby Dick.)
Let’s try something a bit more complicated. outlines has a nice wrapper for all of the models available in the transformers library, so this time we will use one of those. In particular, because we are compiling this blog on a CPU, let’s use GPT2 to find out where we can listen to the songs that inspired the theme of this blog post. For a fair comparison, we’ll check out the unconstrained output first.
from outlines.models import transformersmodel = transformers("gpt2")prompt ="Where can I listen to pink floyd songs online"sequence = generate.continuation(model, max_tokens=30)(prompt=prompt)print(sequence[len(prompt):])
rt in Hawaii via EEOC mobile app, from 6am-1pm EST.
Yikes. Not quite what I had in mind. Let’s see if we can get a more useful output using constrained generation. Here we constrain the generation with a regular expression that matches a subset of URLS
model = transformers("gpt2")rng = torch.Generator()rng.manual_seed(42)prompt ="Where can I listen to pink floyd songs"regex_str ="""(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)[a-zA-Z]{2,20}\.(com|ai|org|edu)"""sequence = generate.regex(model,regex_str, max_tokens=30)(prompt, rng=rng)print(sequence[len(prompt):])
Constrained generation boosts the power of wobbly language models exponentially.
For one final example, let’s really shoot for the stars: using regex to enforce a JSON schema. It is possible6 to do this for general schemas, but in this case, I’m going to do it by hand.
Let’s consider the following schema for generating Pink Floyd singles:
First off, let’s see how GPT2 goes unguided (hint: it won’t do well, but GPT4, for instance, would crush this).
prompt ="""What were Pink Floyd's two most popular singles. Format the output like[ { "title": "Get Back", "album": "Let It Be", "year": 1970, "us-chart-max": 1, "uk-chart-max": 1 }, { "title": "Octopus's Garden", "year": 1969, "us-chart-max": 16, "uk-chart-max": 7 }]"""model = transformers("gpt2-medium")sequence = generate.continuation(model, max_tokens=150)(prompt=prompt, rng=rng)print(sequence[len(prompt):])
1 New Pink Floyd You7 1 Bad Moon Rising State of the Art n/wk Two Extra Cents [1993-11-24]
Pack 1 / Pahnud SPD81/FM [Smack"in] ON1 Overall 2 High Na No Alive Machina 1 Academy [1999-06-21]
Well that is absolute nonsense. And now let’s do constrained generation using the above regex.
It turns out that GPT2 doesn’t really know anything7 about Pink Floyd. But, you know. Pobody’s nerfect.
Anyway. The point of this wasn’t so much that you can make a LLM magically answer any question through the power and the majesty of regex, but rather that you can make even a sub-par LLM conform to a given specification. And it takes the same amount of time as unguided generation.
Now that we have seen what outlines can do, let’s take a look at how it happens.
A peek under the hood
Run Like Hell
If you are a sane person, the words “regular expression” throw you back to that time where you searched “validate email addresses regex” and ended up on Stack Overflow8. There, you found a cryptic incantation of the sort:
Praying to the Computer gods, you feverishly pressed Ctrl-C, Ctrl-V with trembling fingers and that was it. Today is your lucky day: before getting into guided generation we need to demystify regular expression. Don’t run just yet.
Regular expressions were invented to specify match patterns in text, and their most common use is to “find” a pattern in a string. If you ask ChatGPT What are the first 10 digits of pi? it will answer:
The first 10 digits of pi (π) are as follows:
3.1415926535
Not ideal if you’re calling the API and all you care about is the digits of pi. You thus need to find a way to extract the number from the answer. A regular expression that will match the number is [0-9]+\.[0-9]+9. In human language, “One or several digits between 0 and 9, followed by a period, followed by one or several digits between 0 and 9”. The library re in Python’s standard library contains an algorithm that uses regular expression to “find” such pattern in a string:
import reanswer ="""The first 10 digits of pi (π) are as follows:3.1415926535"""regex ="[0-9]+\.[0-9]+"print(re.search(regex, answer))
which means “Found a substring that matches the input regex, it spans the 47th to the 59th character in the input string”. re also allows us to find and replace substrings that match a regular expression:
import reregex ="[0-9]+\.[0-9]+"print(re.sub(regex, "3.14159", "A floating-point number: 1.2"))
A floating-point number: 3.14159
Or to determine if the input matches the expression
import reregex ="[0-9]+\.[0-9]+"print(re.match(regex, "No number here"))
None
Another useful feature of regex processors is the ability to perform partial matches. A partial match is a string that matches up until its last character, thus one for which we could find completions that would have matched the pattern. This does not come with Python’s standard re library, but the regex library provides the functionality.
Say the pattern is a series of 3 letters followed by 1 digit [a-z]{3}[0-9]. The string “ab” is a partial match since we can still build a string that matches the pattern using “ab” as a prefix:
import regex as reregex ="[a-z]{3}[0-9]"print(re.match(regex, "ab", partial=True))
However, “0” is not a partial match: no possible completion can lead to a string that matches the pattern:
import regex as reregex ="[a-z]{3}[0-9]"print(re.match(regex, "0", partial=True))
None
To summarize, regular expressions are a language that allows us to express patterns in text, and libraries can use a regex processor to find (sub)strings that match a given pattern. And if we’re able to match patterns, we’re also able to generate text that matches this pattern.
High hopes
That was about all the knowledge about regular expression you need to design a first algorithm that ensures that the output of a LLM matches a given pattern:
Start the generation with an empty prefix (the empty string).
Concatenate every token of the vocabulary to the prefix. This gives you the set of all possible completions.
For every possible completion use regex’s partial match feature to determine whether it can lead to a completion that matches the regex pattern. If that’s not the case, mask the token by setting its logit value to \(-\infty\).
Use the masked logits to sample a new token.
Concatenate the new token to the prefix and go back to (1).
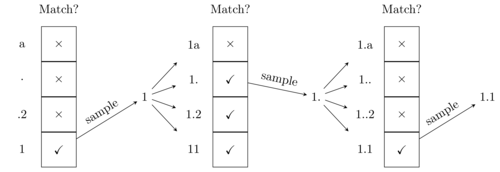
Going back to our floating-point example, let’s assume that we would like to generate a string that matches the regex [0-9]+\.[0-9]. The vocabulary of our model is ["a", ".", ".2", "1"] Starting with the empty string ““, the following diagram illustrates the process we just described:
Illustration of the naive regex-guided generation process that loops over the entire vocabulary to find matches at each step
At first, only {"1"} is a valid completion so we generate "1". Then of all the possible next completions, only {"1.", "1.2", "11"} partially match the regex, so we sample the next completion among these choices. Finally, having sampled "." the only valid choice is "1".
The following code provides a simple implementation for a toy model that would assign equal probability to every token at each step:
import mathimport numpy as npimport regex as refrom scipy.special import softmaxnp.random.seed(30217)logits = np.array([1., 1., 1., 1.]) # Random model with equal probabilitiesvocabulary = ["a", ".", ".2", "1"]regex ="[0-9]+\.[0-9]+"completion =""for _ inrange(4):# Build the logit mask mask = []for token in vocabulary: tentative_completion = completion + token match = re.fullmatch(regex, tentative_completion, partial=True)if match isNone: mask.append(-math.inf)else: mask.append(0) mask = np.array(mask) masked_logits = logits + mask# Sample the next token probs = softmax(masked_logits) next_token_id = np.random.choice(len(vocabulary), p=probs) completion += vocabulary[next_token_id]print(completion)
1.211
This will work for any regex pattern supported by the regex library, and does not depend on the tokenization shenanigans that LLM researchers make the rest of us suffer through. Isn’t this lovely?
Bad news: this algorithm will explode in your face. The typical vocabulary \(\mathcal{V}\) of a large language model contains roughly \(50,000\) (fifty thousand) tokens, which means that for each token you want to generate you will need to perform \(50,000\) partial matches. In a language like Python, the time spent performing partial matches will easily dominate the time it takes to generate the next token. While we’ve just solved the problem in theory, this solution is unusable in practice.
Welcome to the machine
I have good news and bad news for you. The good news is we can do regex-guided generation without introducing latency. The bad news is that you’ll have to understand how regex processors like regex work under the hood. In the following I will expand the explanation of the method we gave in our paper, and you can refer to it and the implementation in Outlines.
The first thing that a regex processor might do is translate the regular expression into an internal representation called a Deterministic Finite Automaton (DFA), which is a kind of Finite-State Machine (FSM). DFA is a big name to designate a simple model of computation where there are several states and rules for moving from one state to another; it is designed to accept or reject a string of symbols by running it through a state sequence.
Here is how the matching proceeds:
Start in state 0 with the full string;
Pop the first character of the string. If it matches any transition rule, it moves to the corresponding state. Otherwise we terminate and reject the string;
Iterate until the string is either rejected or you reach one of the DFA’s final (also called accept) states.
What does the DFA look like for a given regular expression? Let’s consider a slightly more complex regular expression than previously, ([0-9])?+\.[0-9]+,10 and use the interegular Python library to translate it to its equivalent DFA representation:
There’s a lot to unpack in this output. The first column corresponds to the names of the FSM states and are somewhat arbitrary. The second column tells us whether or not the states are final/accept states, i.e. states indicating a possible match:
print(fsm.finals)
frozenset({4, 5})
Each of the following columns correspond to an element of the FSM’s alphabet, i.e. the set of admissible characters. Any character outside the alphabet cannot be used to build a string that matches the regular expression.
print(fsm.alphabet)
0-9 | 0
anything_else | 1
. | 2
Finally, elements of the table correspond to possible transitions. These rows can be interpreted as follows.
This pattern optionally contains one or more numbers [0-9], followed by a ., followed by one or more numbers [0-9]. From this description, we can list out the possible states.
The initial state. The only acceptable transitions from this state is a digit [0-9] (to state 1) or a . (to state 2). This cannot be a terminal state.
Corresponds to the first number in a sequence that starts with [0-9]. As such, it cannot be a terminal state as the minimum matching string has at least on . in it. The next state is either a . (state 2) or another number, which we will label state 3.
Corresponds to the . character in a sequence. This cannot be a terminal state and the next state must be a [0-9] (state 4)
Corresponds to any [0-9] after the first one but before the . symbol. The next state will either be a . (state 2) or another [0-9] (stay in state 3). This cannot be a terminal state as the string does not have a . in it yet.
Corresponds to a number [0-9] that comes immediately after.. This can be a final state. If the machine continues it goes to state 5, another [0-9].
Corresponds to any number [0-9] that cannot have a . after it. This is a valid final state, and if the machine continues it will stay in state 5.
We can find these transitions in a somewhat easier way to read in fsm.map:
interegular made the unfortunate choice of designating both FSM states and alphabet elements with numbers, which is very confusing at first. The map above had the structure state -> alphabet_element -> new_state. It is still a bit more readable than the table above.
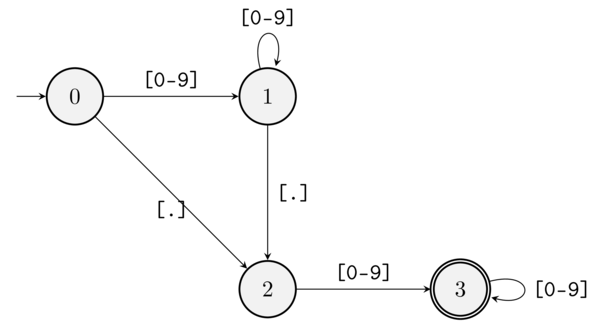
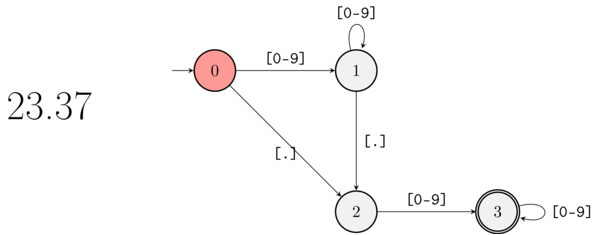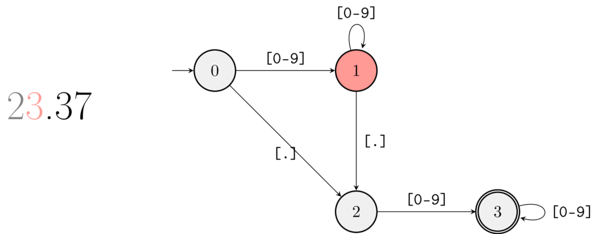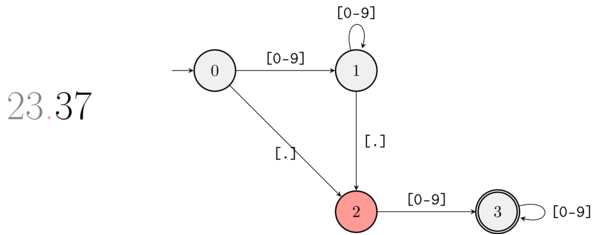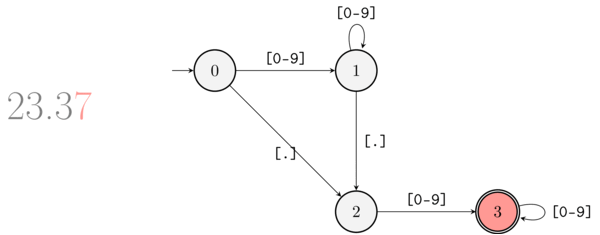
There’s an even simpler way to represent the previous FSM, with a diagram. By now you should be able to read the diagram that represents the FSM-equivalent of ([0-9]+)?\.[0-9]+ without extra explanation:
The FSM corresponding to ([0-9]+)?\.[0-9]+ as a diagram. The double circle denotes a terminal node.
And the following animation illustrates what happens when the string “23.37” is matched by the regular expression processor:
A gif showing how the FSM moves while parsing 23.37.
If you’ve understood this, congratulations! Gone are the days where you crashed production because you copy/pasted a regex from ChatGPT without understanding it. This can get slightly more complicated in practice, especially since programming languages tend to add non-regular extensions to regular expressions. But this should be enough to get you started.
Careful with that Axe, Eugene
The next conceptual leap is to realize that we can reverse this process, and instead of using the DFA to validate sequences of symbols we can use it to generate sequences that are necessarily valid. We start with an empty prefix, then select the subset of the vocabulary that would match the possible transition, sample one element from this subset, move on to the next state and repeat until you end up in one of the DFA’s accept states.
If our vocabulary is only made of single characters the solution is simple. We just look at the map of the DFA! As we progress through the completion we can advance the state of the DFA, and fetch the next valid tokens with a dictionary lookup.
Unfortunately for us the vocabularies used to train large language models are an unholy mess, where each element of the vocabulary is a string that contains one or several symbols. The processing step is slightly more complicated. But wait for it… we can pre-process the vocabulary and compute the subsets that correspond to each state before starting the generation. This requires only one pass through the vocabulary. Then, during generation, masking the vocabulary tokens is a simple dictionary lookup and guided generation is just as efficient as unguided generation.
For each state of our FSM, we have a collection of transitions. For example, in the previous section, state 1 had the transitions 1->2 and 2->3. The fsm.map function stores these as a dictionary of dictionaries. Now lets use them for something cool.
For each token token in the vocabulary (with corresponding token_id), let’s imagine that we can check to see if either token satisfies the regex (the FSM terminates) or it does not match (the FSM does not terminate). We could call this function partial_match. We could use this as follows to construct a dictionary for each state of the FSM.
First we need to figure out whether tokens in the vocabulary correspond to a valid path between states of the DFA. This is what the following function does. If a token corresponds to a valid path, like “.2” we return the visited states. If it doesn’t, like ” The” we return None. Substrings of some tokens like “.2aabb” can correspond to path in the DFA, but lead to generations that won’t match the regular expression, so we add a condition to exclude them.
from collections import ChainMap, defaultdictdef partial_match(transitions, token):"""Partially match the token to the DFA starting from `transitions`. `transitions` is a map `alphabet_element -> state` that represents the valid transitions from a given state of the DFA. We iterate over the token's symbols, and at each step transition to the next state if we find a valid transition. We stop the walk when either the current state is an accept state of the FDA or if we end on a state from which there is no possible transition. We return the index of the last matched symbol in the token string as well as a tuple that contains the sequence of traversed states. """ state = fsm.initial fsm_map = ChainMap({fsm.initial: transitions}) traversed_states = ()# Iterate over the token's symbols, trying at each step to transition# to a new DFA state.for i, symbol inenumerate(token): alphabet_idx = fsm.alphabet[symbol]ifnot (state in fsm_map and alphabet_idx in fsm_map[state]):if state in fsm.finals: i -=1# last match was on the previous tokenbreakreturnNone state = fsm_map[state][alphabet_idx] traversed_states += (state,) terminated = state in fsm.finalsifnot terminated and state == fsm.initial: # We haven't movedreturnNoneif i <len(token) -1:returnNonereturn traversed_states
To build a map from the DFA’s states to tokens that correspond to valid completions, we need to loop over the states of the DFA, and for each state loop through the vocabulary to check whether tokens correspond to a valid path starting from this state:
# Map from the DFA states to the tokens that correspond to a valid transition# from this state.states_to_vocab = defaultdict(set)# We iterate (once) through the vocabularyfor token_id, token inenumerate(vocabulary):# We look from partial matches starting from each state of the DFAfor state, transitions in fsm.map: path = partial_match(transitions, token)# If partial matches have been foundif path isnotNone: states_to_vocab[state].add(token_id)
The generation can now proceed as follows:
Start in state 0. Look for the tokens that lead to valid completions starting from 0 with states_to_vocab[0].
Mask the logits returned by the LLM so only these tokens can be sampled;
Sample a new token using the logits. Look at the path that corresponds to (0,token), the last state of the path corresponds to the next state of the DFA, new_state;
Look for the tokens that lead to valid completions starting from new_state with states_to_vocab[new_state].
Go to (2) until the FSM is in one of its terminal states and this terminal state has no transition.
Before closing, let me insist again on the fact that the latency introduced by this method is not only negligible (a dictionary lookup at every step), it is also independent of the model size. More details can be found in the paper or in the implementation in Outlines.
Shine On You Crazy Diamond
So what? This work has several implications, some deep, some more practical.
Let’s start with the light stuff. You can define regular expressions that match integers, floating-point numbers, dates, email addresses, URLs, you name it. Instead of using them to parse the output of ChattyGPT (and potentially make errors), you can use them to guide the generation and obtain the result in the desired format directly. If your LLM interfaces with a production system that expects output with a given structure, say JSON with a well-defined schema and field types, you can guide the generation and guarantee that the output will be valid 100% of the time.
Now for the deeper stuff. Current generation algorithms in libraries like transformers, guidance, LMQL already implement some constraints. For instance:
Terminate generation when an EOS token is found;
Terminate generation after a given string was generated;
Terminate generation after a given number of tokens was generated;
Choose completion between different option.
It turns out that every.single.one. of these constraints can be represented in the DFA framework. Since there exists an equivalence between DFAs and regular expression, this also means we can construct a regular expression that corresponds to said constraints. In other words, the generation constraints that are currently being used are a particular case of what we just did here. Augmenting generation with a DFA is thus a very natural generalization of what is currently being done.
Of course, there’s more. As we described in our paper, we can do the same for Context-Free Grammars. Which means generating valid Python, SQL, haikus, you name it. But you must be very tired right now, so we’ll come back to it in another blog.
What’s next?
At the core of Normal Computing’s mission is bridging artificial intelligence, particularly generative AI, to high stakes enterprise decision-making applications. CFG-guided generation is an important milestone in that journey. We are approaching these problems with a mix of interdisciplinary approaches across the full stack, from software infrastructure and algorithms to hardware and physics - if you are interested in pushing the boundaries of reliable AI with us, get in touch at [email protected]!
The gzip model is a LLM in the same way that a block of cheese carved into the shape of a fish is seafood. It turns out that a model that produces logits proportional to the length of the compressed string with that token appended is, well, a very very bad LLM. Ceci n’est pas une LLM!↩︎
More realistically, GPT2 didn’t try to generate JSON from this prompt and, therefore, the thing it did generate was not a good response to the prompt.↩︎
That’s how you can tell I’m old. Cool kids use ChatGPT.↩︎
Heavily simplified for pedagogical purposes. Don’t use this for any kind of serious work.↩︎
This means that the first digits are optional. I was going to keep the regex the same originally, but made a mistake when generating the figures. Since I’m lazy, I figured it was easier to just change the regular expression in the text.↩︎