import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
wikipedia = """Alexander Grothendieck (/ˈɡroʊtəndiːk/; German pronunciation: [ˌalɛˈksandɐ ˈɡʁoːtn̩ˌdiːk] (listen); French: [ɡʁɔtɛndik]; 28 March 1928 – 13 November 2014) was a stateless (and then, since 1971, French) mathematician who became the leading figure in the creation of modern algebraic geometry.[7][8] His research extended the scope of the field and added elements of commutative algebra, homological algebra, sheaf theory, and category theory to its foundations, while his so-called "relative" perspective led to revolutionary advances in many areas of pure mathematics.[7][9] He is considered by many to be the greatest mathematician of the twentieth century.[10][11]
Grothendieck began his productive and public career as a mathematician in 1949. In 1958, he was appointed a research professor at the Institut des hautes études scientifiques (IHÉS) and remained there until 1970, when, driven by personal and political convictions, he left following a dispute over military funding. He received the Fields Medal in 1966 for advances in algebraic geometry, homological algebra, and K-theory.[12] He later became professor at the University of Montpellier[1] and, while still producing relevant mathematical work, he withdrew from the mathematical community and devoted himself to political and religious pursuits (first Buddhism and later, a more Christian vision).[13] In 1991, he moved to the French village of Lasserre in the Pyrenees, where he lived in seclusion, still working tirelessly on mathematics and his philosophical and religious thoughts until his death in 2014.[14]
"""
tokenizer = AutoTokenizer.from_pretrained('EleutherAI/gpt-neox-20b')
memory_ids = tokenizer(wikipedia, return_tensors='pt')['input_ids']
model = AutoModelForCausalLM.from_pretrained("normalcomputing/extended-mind-mpt-7b", external_memories=memory_ids, trust_remote_code=True)Today’s popularized large language models are optimized for the task of producing sequences of tokens that look like they could’ve been present in the training corpus. This is quite distinct from the ways in which LLMs are wielded in such user interfaces as ChatGPT or Perplexity.ai, where users expect the model to perform complex reasoning tasks and faithfully retrieve factual, topical information. If we hope to use the model as a general reasoning agent and not as a stochastic parrot, we need to provide it with any relevant data at inference time, rather than rely on (1) the salient data having appeared in the training corpus and (2) the model being able to recall said data. Further, surfacing references or citations that highlight which content the model used during its generation is crucial for building applications that truly augment human workflows.
This has prompted much development on methods colloquially referred to as “retrieval”1. Or, methods that help LLMs make use of pertinent documents. In context learning, or placing the relevant documents in the context window before the prompt, is the obvious first step. However, in many cases we’re faced with documents longer than the context window of the model. RAG2 attempts to sidestep this by selecting the best subset of documents to include alongside the user’s query. While often effective, RAG is fundamentally limited by the need for a separate search engine. We can’t, for instance, ask the model questions which require synthesizing the entire set of documents. Further, since the retrieval happens before the generation, the best we can do r.e. explainability is report which text was included in the prompt itself. This says nothing about what text the model actually used during generation.
Finetuning3 seeks to extend the length of the context window itself. Running even a few epochs of training can be a non-trivial undertaking for today’s large models, even with a dedicated ML team. Further, these methods doesn’t contribute to the model’s interpretability. Other methods4 suggest structural changes to the model. Many of these are exciting, but most require training from scratch or fine-tuning, making them difficult to leverage with pre-trained models.
In this post, we propose and open source extended mind transformers, which generalize RAG internally. This simple mathematical generalization buys us the performance gains (and more) of RAG, as well as introducing net-new generation controls and granular causal citations. We also get the best of both worlds when it comes to ease of use: seamless integrations (everything is internal to the model), and no fine-tuning required!

Aesthetics for Extended Mind Transformers
As motivation, we provide context from the Philosophy of Mind which served as inspiration for the naming convention and methodology. In Clark and Chalmers (1998) “The Extended Mind”, they present the thesis that external information which is constantly and immediately accessible, and automatically endorsed should be considered part of the memory. And further, that this extension should be considered part of the mind. They term this idea active externalism. The story of Otto functions as an intuition pump:
“[L]ike many Alzheimer’s patients, [Otto] relies on information in the environment to help structure his life. Otto carries a notebook around with him everywhere he goes. When he learns new information, he writes it down. When he needs some old information, he looks it up. For Otto, his notebook plays the role usually played by a biological memory. … The information in the notebook functions just like information constituting an ordinary non-occurrent belief; it just happens that this information lies beyond the skin.”5
In this piece, we present active externalism for LLMs, a mechanism for bolstering the memory of transformers aesthetically inspired by the Extended Mind Thesis. We call transformers which implement active externalism, extended mind transformers.
Extended Mind Transformers
Definition
Our proposed method, which closely resembles the work of Wu et al. (2022)6, is a simple change to the self-attention mechanism. In addition to the causal self-attention integral to transformers, we also allow each query token to attend to a fixed number of “external memories”. These memories are stored in a non-differentiable cache. The choice of which memories to attend to is made using cosine similarity within each decoder layer and attention head. More precisely, our attention computation is described by:
\[ \operatorname{softmax}\left(\frac{Q(K_{R}\oplus K_{L})^{T}}{\sqrt{d}}\right) \times \left(V_{R} \oplus V_{L}\right) \]
Where \((K_{L}, V_{L})\) are key-value pairs from local context, and \((K_{R}, V_{R})\) are key-value pairs from external memories, and \(\oplus\) refers to tensor concatenation. We mask the attention weights such that each query token can only attend to its own retrieved keys, and not those retrieved by previous or following query tokens. In the experiments we present below we use models trained with linear biases rather than positional encodings. When we apply these linear biases to our attention weights, we assign the same index to all retrieved memories.7
Importantly, active externalism retrieves memories exactly - it doesn’t summarize or otherwise dampen memories except through the linear biases.
We generate the external memories (key-value pairs) once, and then pass the representations to each decoder layer in an analogous fashion to passing previous “cached” key-values8. In order to speed up the top-k cosine similarity computation we can use a vector database designed exactly for this purpose9.
We argue that this way of attending to external memories or beliefs is the natural and optimal generalization of methods like RAG, and closely mimics the kind of relationship Otto has with his notebook. The information is constantly and immediately accessible, automatically endorsed, and reliably referenced. We set a similarity threshold such that we always reference our external memories (for every generated token, within all decoder layers), but discard keys that don’t meet some low similarity threshold10 to avoid confusing the model with irrelevant information.
Active externalism is not conceptually difficult to implement, but does require getting familiar with a particular model’s implementation since details like the way key-value pairs are stored and read into the self-attention computation need to be hijacked.
Benchmark Results
Perplexity Experiments
We use perplexity as a metric for model performance. Perplexity is a measure of uncertainty of the model over each generated token, closely related to our cross-entropy loss function. For a full explanation of perplexity as a metric, we suggest checking out this excellent post.
We show results below for perplexity experiments on the Wikitext-103 benchmark11 using Mosaic’s MPT-7b model. We use a stride of 512 tokens in our perplexity experiments, meaning each token is conditioned on at least 512 previous tokens, given that there are indeed 512 tokens to condition on.
Our active externalism method batches each sequence into chunks of increasing length (x-axis), and attends to tokens previous to the last 2048 (max sequence length) as external memories. We show results for varying k, where k is the number of memories we retrieve per query token. We compare active externalism to two baseline methods. The “truncated” baseline simply throws out any tokens previous to the last 2048 during perplexity computations, and the “naive” method which uses all input-length tokens, no matter how long the sequences become.
In the case of the naive method, we observe exactly the phenomenon active externalism seeks to ameliorate: after sequences exceed lengths greater than 2-3k tokens, the performance quickly drops off (in this case, perplexity blows up).
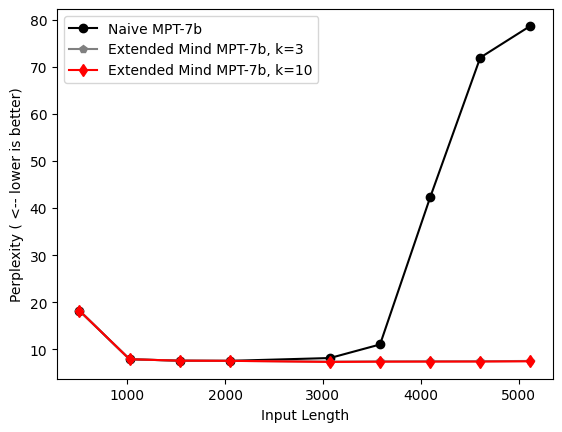
While we can see that active externalism provides clear benefits over simply doing local attention, in the case of the truncated benchmark. Even more exciting, perplexity continues to decrease as we increase the number of retrieved memories per query token.

Retrieval Experiments
We also measure performance on retrieval benchmarks, and compare with RAG and simple baselines. Our dataset is a modified version of the recently released Long context WikiQA benchmark from Abacus.AI.
Our goal is to measure retrieval abilities over varying document lengths, but we also want to control for facts memorized during training, so we edit the dataset by changing the labeled answers to realistic but wrong answers. I.e, we replace every instance of “Lee Hazlewood” with “Terry Allen” in the Wikipedia entry for the song “These Boots Were Made For Walking”, and then ask the model to produce the songwriter’s name, with the correct answer now being “Terry Allen”.
Our intention is to measure the model’s ability to prioritize in context or in memory facts over those it memorized during training. Again, we feel this is an important ability if we’re asking LLMs to be reasoning agents in an evolving world.
In the results below, baseline receives no context at all for the question (we ask it point-blank), RAG selects the best ~2-3k tokens out of the document to include in-context12, and active externalism puts the entire document in memory and uses it as Otto uses his notebook.
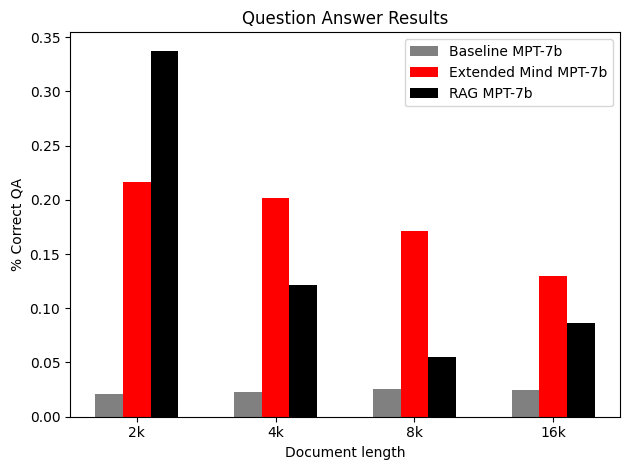
We see that while RAG methods drop off with input length, active externalism continues to be effective. While models finetuned to use longer contexts do currently outperform active externalism on some long-range retrieval tasks, active externalism appears to be a more effective way to do retrieval over long contexts for smaller models.
Where active externalism clearly outperforms RAG in large models is precisely where the model has memorized before overfitting. Or, the model’s weights encode factual information even as the model’s performance on test data14 continues to improve. Depending on your application, this could be seen as a strength or shortcoming. Certainly when we use LLMs as reasoning agents, this is a shortcoming.
Using active externalism also appears to eliminate some reliance on prompting. Whereas usually we’d need to include some examples of the kind of responses we hope to observe in the prompt (or use a “chat” model which has been RLHF’ed), we observe experimentally that this isn’t necessary when using active externalism.
Impact on reasoning engine
We discuss two important consequences of active externalism on the LLM’s ability as a reasoning agent: uncertainty awareness and abstraction levers.
If we prompt the model with a question it’s unsure about15, it may not respond in a way that’s transparent about that uncertainty. Active externalism provides a new method for revealing when a model is uncertain about its answer.
Let’s look at an example. We load our model easily from huggingface, and pass a paragraph from Wikipedia’s entry on Grothendieck as external memories.
Now, let’s ask the model a question we know is answered (albeit a little obscurely) in the above paragraph without using active externalism. We can achieve this by setting the parameter model.use_active_externalism = False or simply passing topk=0. Hint: the correct answer is 1971.
prompt = "When did Alexander Grothendieck get his French citizenship?"
input_ids = tokenizer(prompt, return_tensors='pt')['input_ids']
out = model.generate(input_ids, max_length=input_ids.size(-1)+50, topk=0)
print('Baseline Generation: ', tokenizer.decode(out[0]))Baseline Generation: When did Alexander Grothendieck get his French citizenship?
I am trying to find out when Alexander Grothendieck got his French citizenship. I know that he was born in Germany and that he got his French citizenship in the late 1950s. I am trying to find out when he got hisNow let’s enable active externalism, slowly cranking up the number of memories each query token is allowed to attend to using the topk parameter.
out = model.generate(input_ids, max_length=input_ids.size(-1)+15, topk=5)
print('Generation for k=5: ', tokenizer.decode(out[0][input_ids.size(-1):]).strip())
out = model.generate(input_ids, max_length=input_ids.size(-1)+15, topk=6)
print('Generation for k=6: ',tokenizer.decode(out[0][input_ids.size(-1):]).strip())
out = model.generate(input_ids, max_length=input_ids.size(-1)+20, topk=7)
print('Generation for k=7: ',tokenizer.decode(out[0][input_ids.size(-1):]).strip())
out = model.generate(input_ids, max_length=input_ids.size(-1)+15, topk=8)
print('Generation for k=8: ',tokenizer.decode(out[0][input_ids.size(-1):]).strip())
out = model.generate(input_ids, max_length=input_ids.size(-1)+20, topk=30)
print('Generation for k=30: ',tokenizer.decode(out[0][input_ids.size(-1):]).strip())Generation for k=5: A: I think he got it in the early 1960s.
Generation for k=6: A: I think he got it in the early 1970s.
Generation for k=7: A: He was born in France, and he was naturalized in 1971.
<|endoftext|>
Generation for k=8: A: I think he got it in 1971.
<|endoftext|>Q
Generation for k=30: A: He was born in Germany, and became a French citizen in 1971.Not only did the model produce the correct answer, but it also expressed increasing certainty about its answer. This evolution of generations signals the model’s original uncertainty.
In cases where the model is certain about the answer, the generations are stable as we increase k over the external context.
prompt = "What was did Alexander Grothendieck's profession?"
input_ids = tokenizer(prompt, return_tensors='pt')['input_ids']
out = model.generate(input_ids, max_length=input_ids.size(-1)+25, topk=0)
print('Baseline Generation: ', tokenizer.decode(out[0][input_ids.size(-1):]).strip())
out = model.generate(input_ids, max_length=input_ids.size(-1)+15, topk=2)
print('Generation for k=2: ', tokenizer.decode(out[0][input_ids.size(-1):]).strip())
out = model.generate(input_ids, max_length=input_ids.size(-1)+15, topk=8)
print('Generation for k=8: ', tokenizer.decode(out[0][input_ids.size(-1):]).strip())Baseline Generation: What was did Alexander Grothendieck's profession?
Alexander Grothendieck was a French mathematician
Generation for k=2: Alexander Grothendieck was a mathematician.
What
Generation for k=8: A: He was a mathematician.
<|endoftext|>Q: WhatA natural extension of this principle might look like the development of a metric based on similarity or attention weight which could communicate this uncertainty in a more compact form, work currently under development at Normal.
The parameter topk also serves as a useful lever for the level of abstraction in the model’s output. E.g., the extent to which we’d like the model to synthesize the memories vs. quote verbatim from the source. We see this clearly in question-answering tasks over code. We show an example using the chat model here, which is best equipped to handle more free form question-answering tasks.
code_snippet = """def sieve_of_eratosthenes(limit):
sieve = [True] * (limit + 1)
sieve[0] = sieve[1] = False
primes = []
for current in range(2, int(limit**0.5) + 1):
if sieve[current]:
primes.append(current)
for multiple in range(current*current, limit + 1, current):
sieve[multiple] = False
for num in range(int(limit**0.5) + 1, limit + 1):
if sieve[num]:
primes.append(num)
return primes
"""
tokenizer = AutoTokenizer.from_pretrained('EleutherAI/gpt-neox-20b')
memory_ids = tokenizer(code_snippet, return_tensors='pt')['input_ids']
model = AutoModelForCausalLM.from_pretrained("normalcomputing/extended-mind-mpt-7b-chat", external_memories=memory_ids, trust_remote_code=True)We ask the model to recall what our function does, first with a small topk.
prompt = "What does the function sieve_of_eratosthenes do?"
input_ids = tokenizer(prompt, return_tensors='pt')['input_ids']
out = model.generate(input_ids, max_length=input_ids.size(-1)+100, topk=2)
print(tokenizer.decode(out[0]))What does the function sieve_of_eratosthenes do?
The function sieve_of_eratosthenes is a Python function that implements the Sieve of Eratosthenes algorithm to generate all prime numbers up to a given limit.
The Sieve of Eratosthenes is a simple algorithm that generates all prime numbers up to a given limit. It works by creating a list of all integers from 2 to the given limit, and then iteratively marking the multiples of each prime number as composite (not prime).We see that with a small topk the model abstracts away the details from the code, providing a natural language description of what the code does. Now let’s try with a larger topk.
out = model.generate(input_ids, max_length=input_ids.size(-1)+100, topk=14)
print(tokenizer.decode(out[0]))What does the function sieve_of_eratosthenes do?(limit):
primes.append(True)
for i in range(2, int(limit**0.5) + 1):
if sieve[i]:
break
else:
for i in range(2, int(limit**0.5) + 1):
if i % 2 == 0:
sieve[i] = False
return primes
```
This implementation of the SNow the model outputs much closer to verbatim code, while abstracting away some variable names. This is the kind of nuanced stylistic choice is very hard to achieve using naive prompting and RAG methods without developing many point solutions specific to the data and prompt. More importantly, this kind of experiment gives us small clues into how the model actually reasons over these key-value pairs. At Normal, we hope to combine work on mechanistic interpretability methods with extended mind transformers, building a unified system for understanding how models store facts and reason over them.
Explainability
Clark and Chalmers write in their paper: “By embracing an active externalism, we allow a more natural explanation of all sorts of actions”, and indeed this is true for our active externalism as well. Using attention weights, we can highlight which memories were used during each generation step. Here we highlight the memories used when generating the correct token “1971”. Since we retrieve memories per layer, per head, we display the mode.

Simple methods like this are just the beginning, but granular citations, in fact causal citations at all, are currently impossible using methods like RAG. The best we can get is highlighting those sections that were chosen to include in context. Using self-attention weights can perhaps buy you something, but this is unwieldy data and it’s explanatory power has been questioned.
Creating external memories
There are many interesting hyperparameters to discuss related to active externalism. Alternative masking strategies, restricting active externalism to some subset of decoder layers, and evaluating the role model size plays are all important discussions. We leave most of the discussion for more technical forthcoming papers. But we felt it was important to mention briefly the hyperparameters used in generating the external memories. We create our external memories (at each layer) by passing those external contexts through our model, just like inference. Then we save the internal representations the model generated, and attend to them later. If our external memories are longer than the model’s maximum sequence length, we’ll usually want to generate our representations using a stride. This ensures that all tokens are conditioned on at least stride-length number of previous tokens. Intuitively, all our memories will have “seen” some reasonable amount of context. However, there are situations where increased context may not be aligned with the model’s best representation of the data. For instance, representations of numerical or log-type data may benefit from using a smaller sequence or stride length.
Summary
At Normal, we believe that there remains a wealth of opportunity to uncover by approaching today’s fractured, albeit proliferative, Enterprise AI landscape from a first principles point of view – even, and arguably especially, where early consensus has begun to form. We strongly believe that interdisciplinary perspectives and research are essential for advancing the field, a fundamentally and historically cross-sectional and constantly evolving discipline.
In “The Extended Mind” Clark and Chalmers conjecture: “In the distant future we may be able to plug various modules into our brain to help us out: a module for extra short-term memory when we need it.”
While this remains a distant goal for humans, we propose a method for achieving exactly this kind of short-term memory boost for LLMs. We’ve shown how a simple and natural extension of the self-attention mechanism for LLMs enables SoTa performance on retrieval tasks over long documents, uncertainty awareness, abstraction levers, granular explainability, and perhaps even given us some insight into the way these models reason internally.
What’s next
We’re excited to extend these methods to models that use rotary and relative position encodings.
Making causal citations an out-of-the-box feature is also high on our list.
Distilling the information from the joint evolution of generations and choices of k into an uncertainty metric is another area we’re investing in.
Finally, continuing to develop and run comprehensive benchmarks will be crucial for building a robust understanding of the benefits provided by active externalism.
References
Buchen, Patrick. 2018. “In Defense of Otto and His Extended Mind.” 2018. https://medium.com/@pnbuchen/in-defense-of-otto-and-his-extended-mind-9786db756f2d.
Burtsev, Mikhail S., Yuri Kuratov, Anton Peganov, and Grigory V. Sapunov. 2021. “Memory Transformer.” https://arxiv.org/abs/2006.11527.
Clark, Andy, and David Chalmers. 1998. “The Extended Mind.” Analysis 58, no. 1: 7–19. http://www.jstor.org/stable/3328150.
Liu, Nelson F., Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. “Lost in the Middle: How Language Models Use Long Contexts.” https://arxiv.org/abs/2307.03172.
Martins, Pedro Henrique, Zita Marinho, and André F. T. Martins. 2022. “\(\infty\)-Former: Infinite Memory Transformer.” https://arxiv.org/abs/2109.00301.
Press, Ofir, Noah A. Smith, and Mike Lewis. 2022. “Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.” https://arxiv.org/abs/2108.12409.
Sukhbaatar, Sainbayar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. 2019. “Augmenting Self-Attention with Persistent Memory.” https://arxiv.org/abs/1907.01470.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. “Attention Is All You Need.” https://arxiv.org/abs/1706.03762.
Wu, Yuhuai, Markus N. Rabe, DeLesley Hutchins, and Christian Szegedy. 2022. “Memorizing Transformers.” https://arxiv.org/abs/2203.08913.
Footnotes
Indeed, retrieval has thus far become a table stakes part of the modeling stack for building LLM apps.↩︎
RAG, a popular method for tackling the short context length of LLMs in application settings, attempts to identify the most salient information in a long text for a given query or task, such that the long context can be cut down to “fit in memory”. This is accomplished using a choice of sentence embedding that’s usually external to the model, chunking the long text and comparing with the query vector using a similarity or distance metric. Many open sourced projects have made implementing such a strategy easier, and the success of “vector databases” demonstrates the rapid adoption of such methods.↩︎
Although there’s no technical reason we can’t throw an arbitrarily long sequence into context, performance using today’s models will drop off quickly after we exceed the sequence length the model saw during training. This inability to generalize is largely due to the use of positional embeddings. While originally (in Vaswani et al. (2023)) only applied once at the beginning of the encoder/decoder stack, in today’s GPT-style transformers positional encodings are usually incorporated at the bottom of each decoder layer. These are unique constants which are either added or multiplied to hidden states in order to encode the index of each token in the sequence. Unless the model is trained further to expect a wider range of positional values, these new tokens quickly become out of distribution. Even given an infinitely long context, faithfully retrieving facts from very long sequences remains a challenge. Recent experiments show that models still struggle to use all the information provided in the larger context window - often forgetting things in the middle in particular, as they show in Liu et al. (2023).↩︎
The architecture described in Martins, Marinho, and Martins (2022) continuously compresses long text inputs such that the text always fits in memory. This has the obvious advantage of supporting input sequences of “infinite” length, but the weakness of summarizing the past such that it necessarily contains less detail. A coarse-grained/RAG analog to this might be using the language model itself to iteratively summarize past inputs and then passing the summary into context. In Sukhbaatar et al. (2019), the authors suggest replacing the feed-forward mechanism in each decoder layer with another attention block, and interpret this “unified mechanism” as an aggregation of global and contextual information. The creative contributors in Burtsev et al. (2021) propose introducing a
[mem]token which they hope the model will learn to leverage as space for storing global information. They implement various decoder architectures which attempt to enforce this with varying strictness. Folks at Mosaic have combatted the lack of generalizing position encodings by using attention with linear biases (as presented by Press, Smith, and Lewis (2022)).↩︎While the authors of this paper believe the model needs to be trained from scratch or at least fine-tuned to be able to make sense of the extra retrieved tokens, we show that using models trained with ALiBi can make sense of these external key-value pairs innately. While they use a non-differentiable cache on one layer, we cache on every decoder layer.↩︎
I.e., the model interprets those retrieved memories as being some constant distance away from the tokens it considers local context. For simplicity’s sake, we choose this constant index to be that directly following the last in-context index. I.e. if we pass the model a sequence of 1200 tokens, the memories in context will all be assigned position 1201. Certainly there’s room to experiment here - for instance you might choose to bias weights closer to the beginning of the memories more than those toward the end - but we find this is a reasonable and effective choice. We hypothesize that these methods will be effective for models trained with relative positional encodings as well, and will pursue this end in future work.↩︎
a popular mechanism for speeding up inference, as a GPT-style transformer’s output only depends on the previous inputs↩︎
We find .25 to be a good choice.↩︎
https://developer.ibm.com/exchanges/data/all/wikitext-103/↩︎
We use OpenAI’s Ada embeddings, and chunk our document into sequences of 500 tokens with no overlap. We order the documents such that the most similar content is closest to the prompt.↩︎
Each split has on average 200 samples, with more samples in the 2k split and fewer as documents become longer.↩︎
Usually, as measured by cross-entropy↩︎
Unsure in an epistemic way, i.e. the model didn’t observe this fact during training/can’t infer from the context↩︎